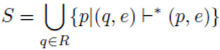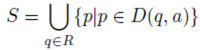Оглавление:
Как вывести матку пчелы?

Основной функцией пчелиной матки является откладка яиц. В семье присутствует только одна плодная особь. О своей родительнице пчелы заботятся и оберегают. У нее есть своя свита, которая обеспечивает ее питанием (маточным молочком).
Пчеловодство для начинающих: как выглядит пчелиная матка?
Пчелиная матка или как ее называют пасечники «Королева» — это родительница всех пчел, живущих в улье. В природе продолжительность ее жизни может достигать до 8 лет, но в пчеловодстве матку обычно по прошествии 2 лет меняют на молодую. Это происходит из-за того, что активный засев яиц происходит в первые два года, потом воспроизводство снижается. Пчеловод может поменять ее и раньше, если она не даёт хороших результатов.
Теперь поговорим о том, как выглядит пчелиная матка. Ее легко можно отличить от рабочих пчел по форме и размерам. Она имеет удлиненное тельце, достигающее размеров 2-2.5 см. Брюшко ее в отличие от остальных пчел выступает за пределы крыльев. В конце имеется жало, но оно применятся для защиты от других пчеломаток.
Имеет меньший размер глаз. Вес — 0.025 гр, а неплодной — 0.020 гр. Вес и размер зависят от возраста пчелы и породы. Матки бывают плодными и неплодными. Первые — делают засев рабочими пчелами, вторые же засевают трутней.
 Вид матки пчелы крупным планом
Вид матки пчелы крупным планом
Сколько время нужно для вывода маток пчелы с нуля естественным путём?
Давайте разберем, как и сколько дней выводится матка пчелы? Тем пчеловодам, которые серьёзно занимаются пасекой, эти знания необходимы по следующим причинам:
- Для смены старой особи на молодую.
- Для племенной работы.
- Для предотвращения роевого состояния пчел.
- Для контроля засевов.
- Поможет выявить трутовку.
- Запишем все правила вывода из [math]A[/math] в виде: [math]A \to A\alpha_1 \mid \ldots \mid A\alpha_n \mid \beta_1 \mid \ldots \mid \beta_m [/math] , где
- [math]\alpha[/math] — непустая последовательность терминалов и нетерминалов ( [math]\alpha \nrightarrow \varepsilon [/math] );
- [math]\beta[/math] — непустая последовательность терминалов и нетерминалов, не начинающаяся с [math]A[/math] .
- Заменим правила вывода из [math]A[/math] на [math]A \to\beta_1A^\prime \mid \ldots\ \mid \beta_mA^\prime \mid \beta_1 \mid \ldots \mid \beta_m[/math] .
- Создадим новый нетерминал [math] \to \alpha_1 \mid \ldots \mid \alpha_n \mid \alpha_1 \mid \ldots \mid \alpha_n[/math] .
- відвідуваність (кожна лекція)
- конспект
- Компиляторы
- Интерпретаторы
- Лексический анализ
-
Синтаксический анализ
- Семантический анализатор
- Редактор связи
-
Генератор кода
- Оптимизация кода
Лексический анализ дает таблицу лексем, которая является входной для следующего этапа.
Синтаксический анализ — определение принадлежности лексем к определенному языку. На выходе — дерево синтаксического разбора.
Семантический анализ (контекстный анализ) — согласование типов переменных, дает атрибутированное дерево.
Генерация промежуточного представления — предпрограмма, дает промежуточный код.
Оптимизатор кода — дает оптимизированную предпрограмму.
- 3 идентификатора
- 3 знака действия
- 1 константа
- front-end. Зависит от исходного языка
- back-end. Постпроцессорные
- Исходная программа
- Лексический анализатор (scaner)
- Синтаксический анализатор (parser)
- Генератор кода
- Скомпилированная программа
Изначально нетерминал [math]A[/math] порождает строки вида [math]\beta\alpha_\alpha_ \ldots \alpha_[/math] . В новой грамматике нетерминал [math]A[/math] порождает [math]\beta[/math] , а [math]A^\prime[/math] порождает строки вида [math]\alpha_\alpha_ \ldots \alpha_[/math] . Из этого очевидно, что изначальная грамматика эквивалентна новой.
Пример [ править ]
[math]A \to S\alpha \mid A\alpha[/math]
Есть непосредственная левая рекурсия [math]A \to A\alpha[/math] . Добавим нетерминал [math]A^\prime[/math] и добавим правила [math]A \to S\alpha
>[/math] , [math] A^ \to \alpha> [/math] .[math]A \to S\alpha
> \mid S\alpha[/math][math]S \to A\beta[/math]
В новой грамматике нет непосредственной левой рекурсии, но нетерминал [math]A[/math] леворекурсивен, так как есть [math] A \Rightarrow S\alpha> \Rightarrow A\beta\alpha> [/math]
Воспользуемся алгоритмом удаления [math] \varepsilon [/math] -правил. Получим грамматику без [math] \varepsilon [/math] -правил для языка [math]L(\Gamma) \setminus \lbrace \varepsilon \rbrace[/math] .
Упорядочим нетерминалы, например по возрастанию индексов, и будем добиваться того, чтобы не было правил вида [math]A_i \to A_j\alpha[/math] , где [math]j \leqslant i[/math] . Если данное условие выполняется для всех [math]A_i[/math] , то в грамматике нет [math]A_i \Rightarrow^* A_i[/math] , а значит не будет левой рекурсии.
Пусть [math]N = \lbrace A_1, A_2, \ldots , A_n \rbrace[/math] — упорядоченное множество всех нетерминалов.
Если [math]\varepsilon[/math] присутствовал в языке исходной грамматики, добавим новый начальный символ [math]S'[/math] и правила [math]S’ \to S \, \mid \, \varepsilon [/math] .
После [math]i[/math] итерации внешнего цикла в любой продукции внешнего цикла в любой продукции вида [math]A_k \to A_l\alpha, k \lt i[/math] , должно быть [math]l \gt k[/math] . В результате при следующей итерации внутреннего цикла растет нижний предел [math]m[/math] всех продукций вида [math]A_i \to A_m\alpha[/math] до тех пор, пока не будет достигнуто [math]i \leqslant m [/math] .
После [math]i[/math] итерации внешнего цикла в грамматике будут только правила вида [math]A_i \to A_j\alpha[/math] , где [math]j \gt i[/math] . Можно заметить, что неравенство становится строгим только после применения алгоритма устранения непосредственной левой рекурсии. При этом добавляются новые нетерминалы. Пусть [math]_i [/math] новый нетерминал. Можно заметить, что нет правила вида [math]\ldots \to _i[/math] , где [math]_i[/math] самый левый нетерминал, а значит новые нетерминалы можно не рассматривать во внешнем цикле. Для строгого поддержания инвариантов цикла можно считать, что созданный на [math]i[/math] итерации в процессе устранения непосредственной левой рекурсии нетерминал имеет номер [math]A_[/math] (т.е. имеет номер, меньший всех имеющихся на данный момент нетерминалов).
На [math]i[/math] итерации внешнего цикла все правила вида [math]A_i \to A_j \gamma[/math] где [math] j \lt i [/math] заменяются на [math]A_i \to \delta_1\gamma \mid \ldots \mid \delta_k\gamma[/math] где [math]A_j \to \delta_1 \mid \ldots \mid \delta_k[/math] . Очевидно, что одна итерация алгоритма не меняет язык, а значит язык получившийся в итоге грамматики совпадает с исходным.
Оценка времени работы [ править ]
Пусть [math]a_i[/math] количество правил для нетерминала [math]A_i[/math] . Тогда [math]i[/math] итерация внешнего цикла будет выполняться за [math]O\left(\sum\limits_ a_j\right) + O(a_i)[/math] , что меньше чем [math]O\left(\sum\limits_^n a_j\right)[/math] , значит асимптотика алгоритма [math]O\left(n\sum\limits_^n a_j\right)[/math] .
Худший случай [ править ]
Проблема этого алгоритма в том, что в зависимости от порядка нетерминалов в множестве размер грамматки может получиться экспоненциальным.
Пример грамматики для которой имеет значение порядок нетерминалов
[math]A_1 \to 0 \mid 1[/math]
[math]A_ \to 0 \mid 1 [/math] для [math]1 \leqslant i \lt n[/math]
Упорядочим множество нетерминалов по возрастанию индексов. Легко заметить, что правила для [math]A_i[/math] будут представлять из себя все двоичные вектора длины [math]i[/math] , а значит размер грамматики будет экспоненциальным.
neerc.ifmo.ru
Организация ввода и вывода сообщений
Подобно многим языкам программирования Visual Basic for Application (VBA) позволяет создать три типа процедур: Sub, Function, Property.
Процедура – это набор описаний и инструкций, сгруппированных для выполнения.
Процедура Sub – набор команд, с помощью которого можно решить определенную задачу. При ее запуске выполняются команды процедуры, а затем управление передается в приложение или процедуру, которая вызвала процедуру Sub. Записываемые макросы автоматически описываются как процедуры Sub, любой макрос или другой код VBA, который просто выполняет определенный набор действий, используя приложения Office, и обычно является процедурой Sub.
Процедура Function (или функция) также представляет собой набор команд, который решает определенную задачу. Различия заключается в том, что процедуры данного типа обязательно возвращают значение. При создании процедуры Function можно описать тип данных, который возвращает функция. Функции обычно используются при выполнении вычислений, операциями с текстом, либо возвращают логические значения.
Процедура Property используется для ссылки на свойство объекта. Данный тип процедур применяется для установки или получения значения пользовательских свойств форм и модулей. Процедуры облегчают хранение и применение информации, если использовать их сначала для сохранения в свойстве этой информации, а затем для ее чтения.
Структура процедуры
При записи процедуры требуется соблюдать правила ее описания. Упрощенный синтаксис для процедур Sub является следующим:
Синтаксис описания функций очень похож на синтаксис описания процедуры Sub, однако, имеются некоторые отличия:
Использование операторов
Процедуры состоят из операторов – наименьших единиц программного кода. Как правило, операторы занимают по одной строке программного кода, и в каждой строке обычно содержится только один оператор, но это не обязательно. В VBA имеется четыре типа операторов: объявления, операторы присваивания, выполняемые операторы и параметры компилятора.
Объявления
Объявление – это оператор, сообщающий компилятору VBA о намерениях по поводу использования в программе именованного объекта (переменной, константы, пользовательского типа данных или процедуры). Кроме того, объявление задает тип объекта и обеспечивает компилятору дополнительную информацию о том, как использовать данный объект. Объявив объект, можно использовать его в любом месте программы.
Переменные – это именованные значения, которые могут изменяться во время выполнения программы.
Рассмотрим пример объявления переменной.
С помощью оператора Dim объявляется переменная с именем МоеЛюбимоеЧисло и объявляется, что значение, которое она будет содержать, должно быть целым:
Константы представляют собой именованные значения, которые не меняются.
Оператор Constant создает строковую константу (текст) с именем НеизменныйТекст, представляющую собой набор символов Вечность:
Оператором Type объявляется пользовательский тип данных с именем Самоделкин, определяя его как структуру, включающую строковую переменную с именем Имя и переменную типа Date с именем ДеньРождения. В данном случае объявление займет несколько строк:
Объявление Private создает процедуру типа Sub с именем СкрытаяПроцедура, говоря о том, что эта процедура является локальной в смысле области видимости. Завершающий процедуру оператор End Sub считается частью объявления.
Оператор присваивания
Оператор присваивания = приписывают переменным или свойствам объектов конкретные значения. Такой оператор всегда состоят из трех частей: имени переменной, или свойства, знака равенства и выражения, задающего нужное значение.
Оператор = присваивает переменной МоеЛюбимоеЧисло значение суммы переменной ДругоеЧисло и числа 12.
В следующей строке кода, записывается, что свойству Color (Цвет) объекта AGraphicShape присваивается значение Blue (Синий) в предположении, что Blue является именованной константой:
В следующеей строке, чтобы задать значение переменной КвадратныйКорень, для текущего значения переменной МоеЛюбимоеЧисло вызывается функция Sqr — встроенная функция VBA вычисления квадратного корня:
В VBA выражением называется любой фрагмент программного кода, задающий некоторое числовое значение, строку текста или объект. Выражение может содержать любую комбинацию чисел или символов, констант, переменных, свойств объектов, встроенных функций и процедур типа Function, связанных между собой знаками операции (например, + или *). Несколько примеров выражений:
itteach.ru
Правила виводу

Экспресс-анализ результатов выборов в Государственную думу показал, что по масштабу фальсификаций они мало отличались от выборов-2011. С учетом того, как проходила регистрация кандидатов и избирательная кампания, можно сказать, что назначение председателем Центризбиркома Эллы Памфиловой вместо Владимира Чурова ничего не изменило. Статистический анализ показывает множество аномалий в результатах 18 сентября; полученные цифры никак не совместимы с предположением о том, что голоса были подсчитаны честно. (Те, кому интересны не статистические, т. е. косвенные, доказательства вбросов, могут посмотреть на доказательства прямые: в сеть выложено множество видеосвидетельств.)
К сожалению, этим простым фактом – «результаты проведенных 18 сентября выборов не представляют мнения российских граждан» – всё и исчерпывается. Свидетельствуют ли результаты «выборов» 18 сентября о популярности Путина, его партии и правительства? Нет. Если бы «Единая Россия» и ее лидеры были популярны, не понадобились бы масштабные вбросы бюллетеней. Есть ли в результатах выборов свидетельства того, что Путин непопулярен и его пребывание у власти близится к концу? Они есть, только если пользоваться принципом «отсутствие свидетельств поддержки есть свидетельство отсутствия поддержки», но это принцип и вообще спорный, а в данном случае есть другие показатели устойчивости режима. Например, в 1991 г., в ситуации, изрядно напоминающей ту, к которой мы идем в последние годы, наблюдалось значительно большее количество проявлений нелояльности к лидеру внутри политической элиты, местных администраций и силовых органов.
Прошедшие выборы ничего не меняют в оценке политической поддержки Путина. Они ничего не добавляют и к тому, что мы знаем о популярности лидеров оппозиции. Если вычесть из результатов «Единой России» те проценты, которые получены с помощью вбросов, доля поддержки оппозиционных партий, конечно, вырастет. Однако комбинация низкой явки и размазанности голосов за оппонентов Путина не дает возможности что-то увидеть здесь. Даже вывод о том, что граждане разочарованы в выборах и не интересуются политикой, сделать, по-хорошему, невозможно. То, что граждане считают бессмысленным участвовать в таких выборах, вовсе не означает, что они не хотят участвовать в настоящих, на которых власть может смениться.
Обидно, что выборы ничего не дали, потому что во многих странах это мощный и тонкий инструмент государственного управления. Он стоит дорого – и дело не в прямых затратах на проведение; настоящие выборы отнимают силы и время и у тех, кто у власти, и у тех, кто хочет их сменить. Однако и выигрыш, по опыту стран – лидеров мирового развития, огромен. А так получается, что мы как будто купили смартфон, но используем его только в качестве будильника. Или фонарика. Конечно, смартфон звенит и светится, но у него есть множество других полезных функций.
Автор – профессор Чикагского университета и НИУ «Высшая школа экономики»
m.vedomosti.ru
Системне програмування-2.Розробка системних програм (20402040)
Систе́мне програмува́ння (або програмування систем) — це вид програмування, який полягає у розробці програм, які взаємодіють з системним програмним забезпеченням (операційною системою), або апаратним забезпеченням комп’ютера.
Павлов Валерій Георгійович [ ред. ]
2 модульні контрольні роботи
Заохочувальні бали надаються за:
Електронний конспект лекцій [ ред. ]
Лекция 1 [ ред. ]
Состав системного программного обеспечения:
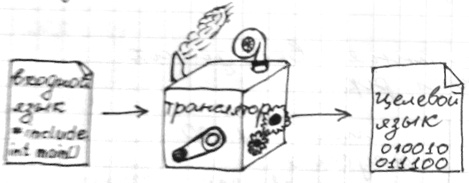
Трансляторы [ ред. ]
Компилятор сначала читает и трансплантирует в бинарный код, а потом выполняет. На выходе — бинарный код.
Интерпретатор выполняет по ходу чтения команд. Не дает бинарный код.
Основные этапы работы компилятора:
2. Дерево синтаксического разбора
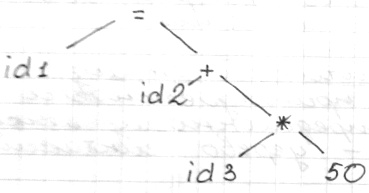
3. Приведение типов в дереве
6. Команды ассемблера будут соответствовать каждой строке
Лекция 2: Принципы построения компиляторов [ ред. ]
Может быть несколько проходов компилятора
При однопроходном компиляторе не всегда удается обозначить метки. Четкого разделения фаз компиляции не существует
Прямая компиляция (по месту)
/*A — исходный язык
* B — целевой язык
* C — язык, на котором пишутся компиляторы
*/Метод раскрутки
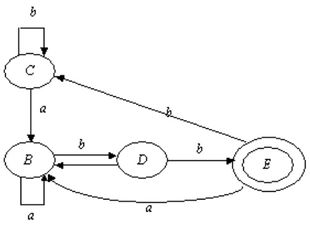
Т-диаграмма (Т-обратная схема)
Имеем компилятор, который переводит, но целевым языком есть язык компилятора
Кространсляция. 2 машины, каждая со своим целевым языком, но мы должны писать язык, когда машина не существует, или не можем использовать
Имеем компилятор из языка P → A, но он недоступен, то мы используем частичный компилятор L → A1, и написать компилятор для несуществующей машины.Использование виртуальной машины (Java, JVM)
Компиляция в 2 этапа:
1. перевод в язык машины
интерпретация в целевой - Компиляция «на лету» (just-in-time compilation)
Развитие метода с виртуальной машиной, когда интерпретация занимает много времени - Естественные — созданы исторически
- Искусственные — созданы людьми
- Четко сформированный набор символов
- Набор правил
Процесс вывода пчеломатки начинается с засева яйца. С плодного яйца выводится матка, которая впоследствии высевает рабочих пчел. Из неплодного засева выводятся трутовки.
В отстроенную на медовых сотах мисочку, матка делает засев яйца. Из него развивается личинка о которой заботятся и оберегают пчелы. Личинку будущей матки кормят маточным молочком и продолжают из мисочки вытягивать маточник. На 7 й день они его запечатывают.
Перед тем, как запечатать, они наполняют его кормом для личинки. Им является маточное молочко. Те пчеловоды, которые собирают его на продажу, как раз это время самое удобное для сбора.
Через сколько дней выводится матка пчелы и выходит из маточника? До выхода из маточника личинка, питаясь молочком, растёт и превращается в куколку. Из куколки в матку. Некоторое время она ещё дозревает в маточнике. На 16 й день происходит выход из маточника, путём его выгрызания.
В первое время после выхода из маточника, молодая матка набирается сил и устраняет остальные маточники. В это же время они разделяются на плодных и трутовок. Плодными становятся те особи, которые в течение 7 дней совершат облёт и спарятся с трутнями. В этом процессе участвует вся семья. Если это произошло то, по прошествии 3 дней в улье должен появиться засев рабочими пчелами.
 Процесс вывода маток. Вызревание маточных яиц
Процесс вывода маток. Вызревание маточных яиц
Плодная матка может жить 5 лет, но для производства мёда так долго ее нецелесообразно держать. Через 2 года ее следует сменить на молодую, потому что после этого времени снижается засев. Осенний засев заканчивается рано, а весенний начинается позже. Если матка не облеталась, то в улье появится трутневый засев. Такая семья обречена на гибель. Трутовку следует удалить и подселить плодную особь.
profermu.com
Устранение левой рекурсии
Методы нисходящего разбора не в состоянии работать с леворекурсивными грамматиками. Проблема в том, что продукция вида [math]A \Rightarrow^* A\alpha[/math] может применяться бесконечно долго, так и не выработав некий терминальный символ, который можно было бы сравнить со строкой. Поэтому требуется преобразование грамматики, которое бы устранило левую рекурсию.
Опишем процедуру, устраняющую все правила вида [math]A \to A\alpha[/math] , для фиксированного нетерминала [math]A[/math] .
Структура языков и их разновидностей [ ред. ]
Язык — это знаковая система, которая используется для общения и познания мира.
Каждый язык должен иметь:
Лекция 3: Особенности языков программирования [ ред. ]
- Искусственные
- Эти языки определяют множество допустимых конструкций
- Все конструкции в языке строятся по определенным правилам
-
Смысл текста программы
Основные правила и определения для грамматик [ ред. ]
(Правила допустимости языка)
Конкатенация обозначает объединение цепочек.
Длина цепочки |α| — количество символов, которые отсутствуют в цепочке.
Декартово произведение 2 цепочек
Язык — множество допустимых символов и цепочек в данной грамматике.
- V * (подмножество) — включает подмножество всех допустимых цепочек с пустой
-
V + (подмножество) — включает подмножество всех допустимых цепочек без пустой
Язык состоит из 2 символов, расположенных в любом порядке, но их количество должно быть одинаковое
Цепочки L1 однозначно соответствуют L4, однако обратного соответствия нет.
Пример 5: конструкция арифметических уравнений
Классификация грамматик [ ред. ]
Порождающие грамматики задаются чтобы задавать класс языков и распознавать допустимые цепочки
Терминальные цепочки — точки входа в язык как ключевые. Если цепочка состоит только из терминальных конструкций, то добавлять ничего нельзя.
Нетерминальные вводит пользователь.
Описать компилятор можно только терминальными символами
- Набор терминальных символов VT
- Набор нетерминальных символов VN
- Дополнительное описание P(набор правил связей VT и VN
-
Начальные значения (S)
Терминальные символы никогда не могут быть в левой части правила, если там нету ни одного нетерминального символа.
В правой могут быть VT и VN.
Если ряд правил имеет одинаковые левые части то при записи правила возможен сокращенный вариант
Проверим грамматику для примера 1:
Нетерминальные обозначают заглавными, а терминальные — строчными
Допустима цепочка из a и b
Лекция 4 [ ред. ]
- L1 =
- L2 =
- L3 — язык скобочных выражений
- L4 — одинаковое количество a и b
- L5 — язык арифметических выражений
Лекция 5: МКР1 [ ред. ]
(2 задания: теория и практика)
Классификация формальных грамматик [ ред. ]
Класс 2: контекстно свободная част слева всегда нетерминал
3. Регулярная грамматика
Любая регулярная грамматика является контекстно свободной. То есть, в левой части выражения может быть 1 нетерминал.
В отличии от КС грамматики на правую часть накладывается дополнительное ограничение 1 терминала. Пустая переменная с 1 терминалом и 1 нетерминалом.
Пример: написать грамматику для языка, допустимые выражения которого являются выражения:
Пишем грамматику языка
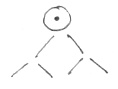
Дерево разбора (выводов) [ ред. ]
Показывает схему разбора выражения в графическом виде
Каждая из ветвей заканчивается терминалом.
2 пути строения:
- от терминалов (восходящее)
- от вершин (нисходящее)
Лекция 6: Грамматический разбор [ ред. ]
Основная задача заключается в том, принадлежит ли исследуемая цепочка символов грамматике.
Грамматика описывается набором правил
Определить принадлежит ли выражение (x + y) + x данной грамматике
Разбор можно проводить путем:
- построения сентенциальной формы
- дерево разбора
При выведении сентенциальной формы — цепочка строится однозначно, однако на завершающем этапе возможны разные варианты
Замена нетерминала терминалами может выполнить несколькими способами. В зависимости от этого могут быть разные последовательности.
Неоднозначность в выведении сентенциальной формы приводит к неоднозначности решения задачи. В дальнейшем предлагаются другие решения.
Для каждой сентенциальной цепочки может быть построено дерево разбора
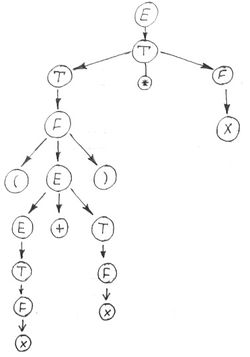
Дерево разбора — графическое представление, где ребра соответствуют правым частям выражения, а узлы (вершины) — левым частям
Для вариабельной сентенциальной формы построить другое дерево
Для обоих форм мы получили одинаковые деревья, так как все правила на дереве не связаны с порядком их применения.
Для данного примера
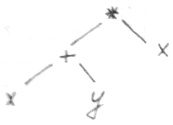

Синтаксические деревья — упрощенные деревья разбора, когда знаки действия вносятся в узлы
Если конструкции дерева совпадают, то существуют методы построения дерева, при котором они не будут повторятся. Это направленные деревья.
Для восходящего построения дерева исходной является анализ. Цепочка a конечной — получение вершины.
Форма Бэкуса-Наура (БНФ)
РБНФ — расширенная БНФ.
Наиболее существенное в РБНФ — использование круглых и фигурных скобок для указания количества повторений.
Преобразование КС грамматик [ ред. ]
Первоначально построенные КС грамматики не всегда оптимальные что приводит к лишним затратам времени при анализе. Поэтому существует метод пост. оптимизации КС грамматик.
- Исключение ε-порождающих правил
- Удаление цепных (цепочных) правил
- Исключение бесполезных нетерминалов (не учтенных ни в одном правиле)
- В КСГ не должно быть недостижимых символов, то есть тех, в которые нельзя перейти
Алгоритм устранения ε-конструкций:
- В правило P’ переписываем все правила из P
- Находим все ε-порождающие нетерминалы
- Добавляем в это множество те, которые могут быть введены через порождающие ε-нетерминалы
- В каждое правило соответствующее этим нетерминалам, используем другое правило в котором перебираются другие нетерминалы в различных сочетаниях
- Удаляем все ε-последовательности
Лекция 7: Исключение цепных правил (где один нетерминал порождает другой) [ ред. ]
Если в грамматике выделяют подмножество тех нетерминалов, которые связанны ценными правилами, то каждое такое правило заменяют перечнем правил того нетерминала с которым данный связан ценным правилом.
Правила могут быть представлены явно и неявно
Мы получаем грамматику эквивалентную G, но на 1 нетерминал больше.
Выписываем все ценные правила и в соответствии с этим дополняем правую часть
Исключение порождающих терминалов [ ред. ]
Непорождающие терминалы не дают возможность породить цепочку без нетерминалов.
Исключение недостижимых нетерминалов [ ред. ]
Нетерминал недостижим если он не участвует в формировании ни одной сентенциальной формы.
Аксиома: анализ правил начинающихся с аксиомы. В правила для получения A и B входят следующие нетерминалы:
Форм. нетерминала c входят в A и C (?)
Лекция 8: Составление цепочки [ ред. ]
Если отдельные цепочки соединены между собой определенным количеством символов, то это правильная цепочка, она попадает в этот язык
Если терминал + нетерминал, то ε никогда не будет
Добавляем терминалы из соединений «терминал + нетерминал», ибо нетерминал может обратиться к ε
Для C другая схема, нужно удалить все правила, что содержат C
Лекция 9: Приведение правил к нормальной форме Хомского [ ред. ]
Грамматика считается приведенной к нормальной форме Хомского, если правые части правил имеют вид:
- — лишь для стартового нетерминала
Правила вида A → Aa преобразуются к виду:
Синтаксические анализаторы [ ред. ]
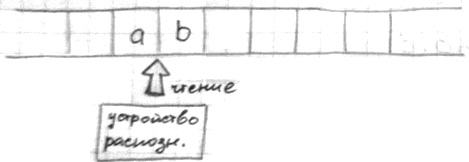
В процессе распознания цепочек, к ним подбирают правила, которые описывают данную грамматику.
S-грамматики [ ред. ]
S-грамматика содержит такие правила, которые начинаются только с терминальных символов. Для разных правил эти символы должны быть разными.

Лекция 10: Построение синтаксических анализаторов [ ред. ]
-
Способ S-грамматики
В S-грамматиках определяющим является 1 символ (терминал). Они еще называются направляющими. -
Способ Q-грамматики
Отличие от S-грамматики — в правой части может находиться пустой символ. Следующий символ это терминальный символ, который может следовать (куди?)Q-грамматика допускает варианты:
первый символ не терминальный
Поскольку существует прием удаления ε-правил в КС грамматиках, то всегда можно привести Q-грамматику в S-грамматику.
Если есть ε, то нужно смотреть правила и тогда на смену first следует follow. Следующий за A терминал, следующий за S терминал.
Поскольку невозможно определить напрямую символ вида first для A, то рассмотрим те правила, в которых в правую часть входит нетерминал. S, первый символ которого будет first, рассмотрим в качестве прав. follow для 4 правила.
Поскольку нетерминал S уч. в левой части правил 1 и 2, то такими, напр, символами будут a и b. Символы a и b являются направленными для 4-го правила.
LL(1) грамматика [ ред. ]
К LL грамматике можно привести Q и S
Число (1) указывает количество анализируемых символов в цепочке (глубина анализа).
Цепочки могут начинаться как с терминала, так и с нетерминала.
Например, символ для 3 правила отсутствует, поэтому все-равно где этот нетерминал (F) уч. в правой части (1,2), однако в них F последний и за ним ничего нету.
В этом случае рассмотрим те правила в которых учитываются левые части правил 1 и 2
Нетерминал E включен в правило 7 и мы можем определить следующий символ.
Ищем сначала правила first, если нет — follow.
Берутся примеры с КС грамматикой
Лекция 11: Правила преобразования грамматик к виду LL(1) [ ред. ]
Для преобразования необходимо выполнить следующие:
- Устранение левой рекурсии
- Факторизация
- Удаление произвольного правила
- Преобразование грамматики списочной структуры
- Замена нетерминального края
Это в конце не гарантирует что мы получим LL(1)
Предварительно грамматика должна быть приведенной к нормальной форме (устранены: ε, цикличность, непорожд. нетерминалы)
Алгоритм 1: если есть правило вида
Вследствие этого мы получаем:
Мы сделали с левой рекурсии правую, которая не запрещена.
Алгоритм 2: такое же исходное, с него получаем:
Этот способ разрешения противоречия, напр, символов для ряда правил за счет перемещения его разрешения на следующий шаг.
Замена нетерминального края
Лекция 12 [ ред. ]
Неудовлетворяющие LL(1) для 1 нетерминала есть правила, которые пересекаются
Выполнили подстановку правой части, потом выполнили факторизацию:
Теперь данная грамматика соответствует.
Преобразование правил в конечные автоматы [ ред. ]
Правила автом. грамматики (нормализация)
Конечный автомат для расцепления цепных символов принадлежит к языку:
количество строк = количеству терминалов количество столбцов = количеству нетерминалов
Матрица переходов — это представление в другом виде.
Роль столбцов и строк выполняют нетерминальные вершины.
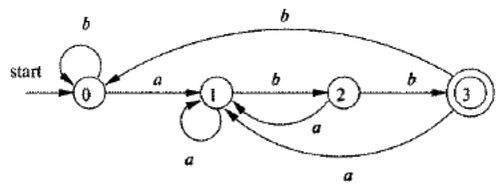
Изобразим конечный автомат в виде графа
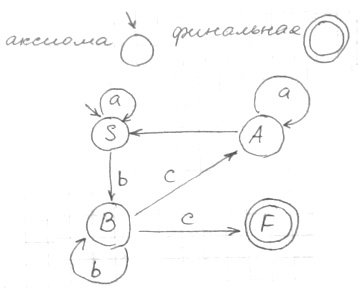
Неопределенность не дает возможности построить детерминированный автомат. При переходе с вершины B под сигналом C возникает неопределенность. Этот автомат не детерминированный.
Переход к детерминированному автомату (ДКА) [ ред. ]
Каждый не детерминированный автомат соответствует детерминированному автомату. ДКА мажет быть получен за счет введения соответствий, которые образуются путем всевозможных сочетаний исходного состава автомата и финального состояния. Если n состояний то возможно 2 n вариантов.
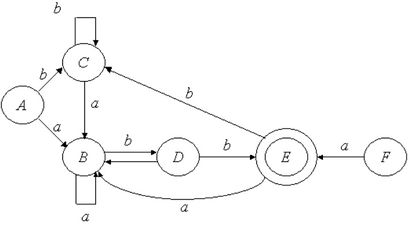
На основе исходной таблицы переходов делаем преобразование и к ней будем добавлять состояния.
Определяем состояние из-за которого автомат не является детерминированным и добавляем их в следующую колонку. Строки заполняем объединением столбцов.
Нужно проверить все ли вершины достижимы, а потом строить автомат. В данном случае F недостижим и оно в графе рассматриваться не будет.
C — финальная вершина ибо в ней присутствует F. Финальных вершин может быть несколько.
Данный граф детерминированный.
Цепочка, принадлежит данной грамматике, если последний символ n переходит в финальную вершину
Лекция 13 [ ред. ]
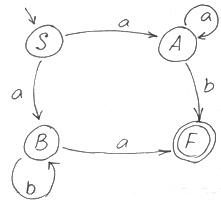
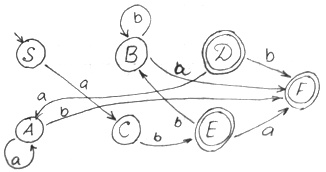
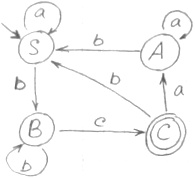
Минимизация [ ред. ]
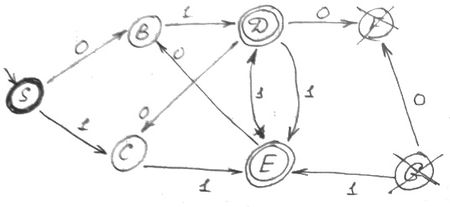
Состояния считаются неразличимыми, если переход из них в конечное состояние осуществляется одинаковыми цепочками символов.
F — переход осуществляется только через конечную
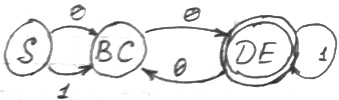
Если вершина не имеет переход на следующую и не является конечной, то ее тоже можно исключить.
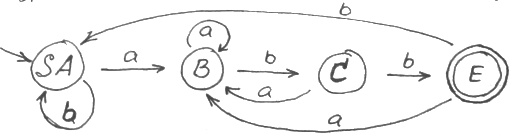
Находим множества неразличимых символов. В данном случае это:
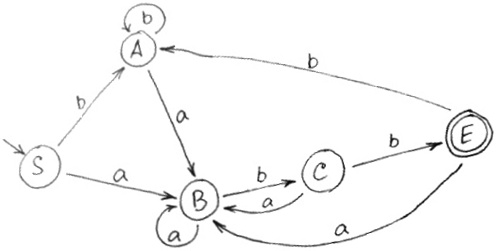
abb делает неразличимыми S и A. Она дает нам основание соединить S и A.
Додаткові матеріали [ ред. ]
1. Алгоритм перетворення граматики до нормальної форми Хомського [ ред. ]
Нормальная форма Хомского — свойство формальной грамматики, если все её продукции имеют вид:
где A, B, C — нетерминалы, α — терминальный символ (представляющий постоянное значение), S — начальный символ, и ε — пустая строка. Также ни B, ни C не может быть начальным символом.
- Если встречается правило вида A → a, то оно переносится без изменений.
- Если встречается правило вида A → BC, то оно переносится без изменений.
- Если встречается правило вида S → ε, то оно переносится без изменений.
- Если встречается правило вида A → aB, то преобразуем его к виду:
А → A’В
A’ → а - Если встречается правило вида A → Ba, то преобразуем его к виду:
А → ВA’
A’ → а - Если встречается правило вида A → ab, то преобразуем его к виду:
А → A’B’
A’ → а
B’ → b - Если встречается правило вида A → aBb, то преобразуем его к виду:
А → A’B’
A’ → A’’B
A’’ → a
B’ → b2. Класи синтаксичних аналізаторів [ ред. ]
Большинство методов анализа принадлежит к одному из двух классов:
- Нисходящие анализаторы, которым соответствуют LL-грамматики
- Восходящие анализаторы, которым соответствуют LR-грамматики
Большинство методов анализа принадлежит к одному из двух классов, один из которых объединяет нисходящие (top-down) алгоритмы, а другой — восходящие (bottom-up) алгоритмы. Происхождение этих терминов связано с тем, каким образом строятся узлы синтаксического дерева: либо от корня (аксиомы грамматики) к листьям (терминальным символам), либо от листьев к корню.
Нисходящие анализаторы строят вывод, начиная от аксиомы грамматики и заканчивая цепочкой терминальных символов. С нисходящими анализаторами связаны так LL-грамматики, которые обладают следующими свойствами:
- Они могут быть проанализированы без возвратов.
- Первая буква L означает, что просматриваем входную цепочку слева на право (left-to-right scan)
- Вторая буква L означает, что строиться левый вывод цепочки (leftmost derivation)
Популярность нисходящих анализаторов связана с тем, что эффективный нисходящий анализатор достаточно легко может быть построен вручную, например, методом рекурсивного спуска. Кроме того, LL-грамматики легко обобщаются: грамматики, не являющиеся LL-грамматиками, обычно могут быть проанализированы методом рекурсивного спуска с возвратами.
С другой стороны, восходящие анализаторы могут анализировать большее количество грамматик, чем нисходящие, и поэтому именно для таких методов существуют программы, которые умеют автоматически строить анализаторы. С восходящими анализаторами связаны LR-грамматики. В этом обозначении буква L по-прежему означает, что входная цепочка просматривается слева направо (left-to-right scan), а буква R означает, что строится правый вывод цепочки (rightmost derivation).
С помощью LR-грамматик можно определить большинство использующихся в настоящее время языков программирования.
3. S-граматики. Вигляд правил, визначення та призначення направляючих символів.Приклад. [ ред. ]
КС-грамматика называется S-грамматикой (а также раздельной или простой) тогда и только тогда, когда выполняются 2 условия:
- Правая часть каждого правила начинается терминалом Ti
- Если два правила имеют совпадающие левые части, то правые части этих правил должны начинаться терминальными символами.
S-грамматика G7.3(S) для этого же языка может использовать для порождения цепочек следующие правила:
Таким чином, направляючі символи дозволяють однозначно визначити, за яким правилом перетворювати нетермінал, не перебираючи все правило.
4. Q-граматики. Вигляд правил, визначення, призначення, пошук направляючих символів. Приклад. [ ред. ]
Поскольку существует прием удаления ε-правил в КС-грамматиках, то применяя его, можно привести Q-грамматику к S-граммматике.
Невозможно определить направляющий символ вида first для правила №4, то рассмотрим те правила, в которых в правую часть входит нетерминал A — 1, 3.
И в том и в другом правиле после A следует нетерминал S. Первый символ которого будет рассматриваться как follow для правила №4.
Нетерминал S участвует в левой части правил 1 и 2, то такими направляющими символами будут a и b.
Начинаются с нетерминала / терминала / ε-символа
Направляющий символ для правила 3 отсутствует, поэтому, находим те правила, где этот нетерминал участвует в правой части. Однако нетерминал F не имеет за собой следующих символов.
5. LL(1) — Вигляд правил, визначення та призначення направляючих символів. Приклад. [ ред. ]
LL(1)-грамматика – это грамматика такого типа, на основании которой можно получить детерминированный синтаксический анализатор, работающий по принципу сверху вниз.
LL(1)-грамматика является обобщением S-грамматики, и принцип ее обобщения все еще позволяет строить нисходящие детерминированные анализаторы. Две буквы L в LL(1) означают, что строки разбираются слева направо (Left) и используются самые левые выводы (Left), а цифра 1 – что варианты порождающих правил выбираются с помощью одного предварительно просмотренного символа.
Необходимым условием того, чтобы грамматика обладала признаком LL(1), является непересекаемость множеств символов-предшественников для альтернативных правых сторон порождающих правил.
Ключевую роль в построении парсеров для LL(1)-грамматик играют множества и .
FIRST (a)— все символы (терминалы), с которых могут начинаться всевозможные выводы из a, а \
FOLLOW(A)— всевозможные символы, которые встречаются после нетерминала A во всех небесполезных правилах грамматики.
Пример определения направляющих символов.
6. Вимоги щодо належності граматики до виду LL(1). [ ред. ]
Условия использования метода рекурсивного спуска
- Метод рекурсивного спуска без возвратов можно использовать только для LL(1)-грамматик
Метод рекурсивного спуска без возвратов можно использовать только для грамматик, правила которых удовлетворяют следующему условию:
Определение. Для КС-грамматики G и цепочки w, состоящей из терминальных и нетерминальных символов, определим множество FIRSTk(w) следующим образом:
Иными словами, множество FIRSTk(w) состоит из всех терминальных префиксов длины K терминальных цепочек, выводимых из w
Пример. Рассмотрим грамматику, порождающую подмножество типов языка Pascal
Для этой грамматики мы имеем:
Понятно, что если цепочка w состоит только из терминалов, то FIRST1(w) — это первые k символов цепочки w, если |w| ≥ k, или это сама цепочка w, если |w| *Aw. Грамматика, имеющая хотя бы одно леворекурсивное правило, не может быть LL(1)- грамматикой. С другой стороны, известно, что каждый КС — язык определяется хотя бы одной нелеворекурсивной грамматикой.
10. Прийоми усунення у правилах граматики лівої рекурсії. Приклад. [ ред. ]
Алгоритм устранения леворекурсивности
Опишем алгоритм устранения непосредственной леворекурсивности. Пусть G = (N, T, P, S) – КС — грамматика и правило
представляет собой все правила из P, содержащие A в левой части, причем ни одна из цепочек vi не начинается с нетерминала A.
Добавим к множеству N еще один нетерминал A’ и заменим правила, содержащие A в левой части, на следующие:
Можно доказать, что полученная грамматика эквивалентна исходной.
В результате применения этого преобразования к приведенной выше грамматике, описывающей арифметические выражения, мы получим следующую грамматику:
Существует еще одни метод удаления левой рекурсии
11. Заміна нетермінального краю, приведення арифметичних виразів. [ ред. ]
Если выявлено пересечение направляющих символов правил при описании в грамматике операторов с метками или массивов в качестве множителя, то выполняется следующее преобразование: заменяется самый левый нетерминальный символ правила, причем, если этот нетерминальный символ имеет К альтернативных правил, то, чтобы не изменить язык, правило должно быть скопировано в К экземплярах и в каждой копии должна быть выполнена замена края соответствующим альтернативным правилом.
Приведение арифметических выражений:
После замены нетерминального края:
12. Роль лівої факторизації у перетворенні граматик. Приклад. [ ред. ]
Левая факторизация — это такое преобразование грамматики, которое делает ее пригодной для предиктивного(нисходящего) синтаксического анализа. Когда не ясно, какая из двух альтернативных продукций должна использоваться для нетерминала, его продукции можно переписать так, чтобы отложить принятие решения до тех пор, пока из входного потока не будет прочитано достаточно символов для правильного разбора.
После левой факторизации:
13. Вилучення довільного правила виводу з КВ-граматики. Приклад. [ ред. ]
Выход. КС-грамматика G’ = (N, ∑, P’, S), такая, что L(G’) = L(G) и A → αBβ ∉ P’.
- Положить G’ = (N, ∑, P’, S)
Удалить правило P → (E) из КС-грамматики G0 с правилами:
E-правила грамматики G будут выглядеть следующим образом:
Из множества правил необходимо удалить заданное правило
и добавить P-правила
Новое множество правил грамматики P’:
15. Граматики у нормальної формі Грейбах. [ ред. ]
Грамматика в нормальной форме Грейбах — контекстно-свободная грамматика (N, ∑, P, S), в которой каждое правило имеет один из следующих четырех видов:
является грамматикой в нормальной форме Грейбах.
Замечание. Некоторые авторы разрешают в грамматиках в нормальной форме Грейбах использовать также правила вида A → αβ, где A ∈ N, a ∈ ∑, β ∈ N
Теорема: Каждая КСГ эквивалентна некоторой грамматике в нормальной форме Грейбах.
Пусть будет G — КС-грамматика, не имеющая цепных правил, бесполезныхсимволов, ε-правил и без правил с левой рекурсией.