
Что такое хеш-таблицы и как они работают
Хеш-таблица (hash table) — это специальная структура данных для хранения пар ключей и их значений. По сути это ассоциативный массив, в котором ключ представлен в виде хеш-функции.
Пожалуй, главное свойство hash-таблиц — все три операции вставка, поиск и удаление в среднем выполняются за время O(1), среднее время поиска по ней также равно O(1) и O(n) в худшем случае.
Простое представление хеш-таблиц
Чтобы разобраться, что такое хеш-таблицы, представьте, что вас попросили создать библиотеку и заполнить ее книгами. Но вы не хотите заполнять шкафы в произвольном порядке.
Первое, что приходит в голову — разместить все книги в алфавитном порядке и записать все в некий справочник. В этом случае не придется искать нужную книгу по всей библиотеке, а только по справочнику.
А можно сделать еще удобнее. Если изначально отталкиваться от названия книги или имени автора, то лучше использовать некий алгоритм хеширования, который обрабатывает входящее значение и выдает номер шкафа и полки для нужной книги.
Зная этот алгоритм хэширования, вы быстро найдете нужную книгу по ее названию.
Учтите, что хеш-функция должна иметь следующие свойства:
- Всегда возвращать один и тот же адрес для одного и того же ключа;
- Не обязательно возвращает разные адреса для разных ключей;
- Использует все адресное пространство с одинаковой вероятностью;
- Быстро вычислять адрес.
Борьба с коллизиями (они же столкновения)
В идеальном случае, когда заранее известны все пары ключ-значение, достаточно легко реализовать идеальную хеш-таблицу, в которой время поиска будет постоянным (используется идеальная хеш-функция, которая определяет положения в таблице по целым значениям и без столкновений).
Но в большинстве случаев приходится бороться с коллизиями. Обычно применяются методы цепочек и открытой индексации.
Метод цепочек
Этот метод часто называют открытым хешированием. Его суть проста — элементы с одинаковым хешем попадают в одну ячейку в виде связного списка.
То есть, если ячейка с хешем уже занята, но новый ключ отличается от уже имеющегося, то новый элемент вставляется в список в виде пары ключ-значение.
Если выбран метод цепочек, то вставка нового элемента происходит за O(1), а время поиска зависит от длины списка и в худшем случае равно O(n). Если количество ключей n , а распределяем по m -ячейкам, то соотношение n/m будет коэффициентом заполнения.
В C++ метод цепочек реализуется так:
# Проверка ячейки и создание списка
Открытая индексация (или закрытое хеширование)
Второй распространенный метод — открытая индексация. Это значит, что пары ключ-значение хранятся непосредственно в хеш-таблице. А алгоритм вставки проверяет ячейки в некотором порядке, пока не будет найдена пустая ячейка. Порядок вычисляется на лету.
Самая простая в реализации последовательность проб — линейное пробирование (или линейное исследование). Здесь все просто — в случае коллизии, следующие ячейки проверяются линейно, пока не будет найдена пустая ячейка.
А алгоритм поиска ищет ячейки в том же порядке, что и при вставке, пока не найдет нужный элемент или пустую ячейку, которая говорит о том, что ключ отсутствует. В случае, если таблица будет заполнена, ее придется динамически расширять.
Метод линейного пробирования для открытой индексации на C++:
# Проверка ячеек и вставка значения
Самое главное
Хеширование и хеш-таблицы применяются для более удобного хранения пар ключ-значение. Если нужна максимальная эффективность, то используйте хеш-таблицы со списками будет намного быстрее, чем обычная таблица.
2 примера денормализации для оптимизации базы данных
Простые и быстрые варианты переноса ключей Redis на другой сервер.
Разделение базы данных на несколько независимых баз
Типы и способы применения репликации на примере MySQL
Как решать типичные задачи с помощью NoSQL
Основные понятия о шардинге и репликации
Как строятся по-настоящему большие системы на основе MySQL
Поиск по большому количеству текста
Как делать перераспределение данных между серверами
Разделение таблиц данных на разные узлы
Быстрый подсчет уникальных значений за разные периоды времени
Худшие практики при работе над растущими проектами
Введение в кэширование данных на примере Memcache
Примеры использования Lua в Nginx для решения стандартных задач
Повышение скорости работы запросов с MySQL Handlersocket
Что такое индексы в Mysql и как их использовать для оптимизации запросов
Примеры использования колоночной базы данных Vertica
Как построить мини CDN на основе распределенного Nginx кеша
Работа приложения с несколькими бэкендами при помощи Nginx
Как и зачем используются очередей сообщений
Правила и практика масштабирования Твиттера
Архитектурные принципы высоконагруженных приложений
Что значит высокая нагрузка (highload) и что при этом делать?
3 аспекта эффективного мониторинга для Web приложений
ruhighload.com
Удаления элемента может быть выполнено за [math]O(1)[/math] , как и вставка, при использовании двухсвязного списка.
Все элементы хранятся непосредственно в хеш-таблице, без использования связных списков. В отличие от хеширования с цепочками, при использовании этого метода может возникнуть ситуация, когда хеш-таблица окажется полностью заполненной, следовательно будет невозможно добавлять в неё новые элементы. Так что при возникновении такой ситуации решением может быть динамическое увеличение размера хеш-таблицы, с одновременной её перестройкой.
При попытке добавить элемент в занятую ячейку [math]i[/math] начинаем последовательно просматривать ячейки [math]i+1, i+2, i+3[/math] и так далее, пока не найдём свободную ячейку. В неё и запишем элемент.
Выбираем шаг [math]q[/math] . При попытке добавить элемент в занятую ячейку [math]i[/math] начинаем последовательно просматривать ячейки [math]i+(1 \cdot q), i+(2 \cdot q), i+(3 \cdot q)[/math] и так далее, пока не найдём свободную ячейку. В неё и запишем элемент. По сути последовательный поиск — частный случай линейного, где [math]q=1[/math] .
Проблем две — крайне нетривиальное удаление элемента из таблицы и образование кластеров — последовательностей занятых ячеек.
Кластеризация замедляет все операции с хеш-таблицей: при добавлении требуется перебирать всё больше элементов, при проверке тоже. Чем больше в таблице элементов, тем больше в ней кластеры и тем выше вероятность того, что добавляемый элемент попадёт в кластер. Для защиты от кластеризации используется двойное хеширование и хеширование кукушки.
- если в цепочке встречается элемент с другим хешем, то он должен остаться на своём месте (такая ситуация может возникнуть если оставшаяся часть цепочки была добавлена позже этого элемента)
- независимые от [math] h_1 [/math]
- в цепочке не должно оставаться «дырок», тогда любой элемент с данным хешем будет доступен из начала цепи
- В редактируемой цепи не остаётся дырок
- Элементы, которые уже на своих местах, не должны быть сдвинуты.
- В других цепочках не появятся дыры
- не равные [math] 0 [/math]
- взаимно простые с величиной хеш-таблицы
- функция должна быть простой с вычислительной точки зрения;
- функция должна распределять ключи в хеш-таблице наиболее равномерно;
- функция не должна отображать какую-либо связь между значениями ключей в связь между значениями адресов;
- функция должна минимизировать число коллизий – то есть ситуаций, когда разным ключам соответствует одно значение хеш-функции (ключи в этом случае называются синонимами ).
- Выполнение операции в хеш-таблице начинается с вычисления хеш-функции от ключа. Получающееся хеш-значение является индексом в исходном массиве.
- Количество хранимых элементов массива, деленное на число возможных значений хеш-функции , называется коэффициентом заполнения хеш-таблицы ( load factor ) и является важным параметром, от которого зависит среднее время выполнения операций.
- Операции поиска, вставки и удаления должны выполняться в среднем за время O(1) . Однако при такой оценке не учитываются возможные аппаратные затраты на перестройку индекса хеш-таблицы, связанную с увеличением значения размера массива и добавлением в хеш-таблицу новой пары.
- Механизм разрешения коллизий является важной составляющей любой хеш-таблицы.
- метод цепочек (внешнее или открытое хеширование );
- метод открытой адресации (закрытое хеширование ).
Хеш-таблицу считаем зацикленной
Теперь докажем почему этот алгоритм работает. Собственно нам требуется сохранение трёх условий.
Противное возможно только в том случае, если какой-то элемент был действительно удалён. Удаляем мы только последнюю ячейку в цепи, и если бы на её месте возникла дыра для сторонней цепочки, это бы означало что элемент, стоящий на [math]q[/math] позиций назад, одновременно принадлежал нашей и другой цепочкам, что невозможно.
Двойное хеширование (англ. double hashing) — метод борьбы с коллизиями, возникающими при открытой адресации, основанный на использовании двух хеш-функций для построения различных последовательностей исследования хеш-таблицы.
Таким образом, операции вставки, удаления и поиска в лучшем случае выполняются за [math]O(1)[/math] , в худшем — за [math]O(m)[/math] , что не отличается от обычного линейного разрешения коллизий. Однако в среднем, при грамотном выборе хеш-функций, двойное хеширование будет выдавать лучшие результаты, за счёт того, что вероятность совпадения значений сразу двух независимых хеш-функций ниже, чем одной.
[math]\forall x \neq y \; \exists h_1,h_2 : p(h_1(x)=h_1(y))\gt p((h_1(x)=h_1(y)) \land (h_2(x)=h_2(y)))[/math]
Есть два удобных способа это сделать. Первый состоит в том, что в качестве размера таблицы используется простое число, а [math] h_2 [/math] возвращает натуральные числа, меньшие [math] m [/math] . Второй — размер таблицы является степенью двойки, а [math] h_2 [/math] возвращает нечетные значения.
Пример [ править ]
[math] h(k,i) = (h_1(k) + i \cdot h_2(k)) \bmod 13 [/math]
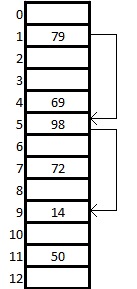
Мы хотим вставить ключ 14. Изначально [math] i = 0 [/math] . Тогда [math] h(14,0) = (h_1(14) + 0\cdot h_2(14)) \bmod 13 = 1 [/math] . Но ячейка с индексом 1 занята, поэтому увеличиваем [math] i [/math] на 1 и пересчитываем значение хеш-функции. Делаем так, пока не дойдем до пустой ячейки. При [math] i = 2 [/math] получаем [math] h(14,2) = (h_1(14) + 2\cdot h_2(14)) \bmod 13 = 9 [/math] . Ячейка с номером 9 свободна, значит записываем туда наш ключ.
Таким образом, основная особенность двойного хеширования состоит в том, что при различных [math] k [/math] пара [math] (h_1(k),h_2(k)) [/math] дает различные последовательности ячеек для исследования.
Простая реализация [ править ]
Пусть у нас есть некоторый объект [math] item [/math] , в котором определено поле [math] key [/math] , от которого можно вычислить хеш-функции [math] h_1(key)[/math] и [math] h_2(key) [/math]
Так же у нас есть таблица [math] table [/math] величиной [math] m [/math] , состоящая из объектов типа [math] item [/math] .
Реализация с удалением [ править ]
Чтобы наша хеш-таблица поддерживала удаление, требуется добавить массив [math]deleted[/math] типов [math]bool[/math] , равный по величине массиву [math]table[/math] . Теперь при удалении мы просто будем помечать наш объект как удалённый, а при добавлении как не удалённый и замещать новым добавляемым объектом. При поиске, помимо равенства ключей, мы смотрим, удалён ли элемент, если да, то идём дальше.
В Java 8 для разрешения коллизий используется модифицированный метод цепочек. Суть его заключается в том, что когда количество элементов в корзине превышает определенное значение, данная корзина переходит от использования связного списка к использованию сбалансированного дерева. Но данный метод имеет смысл лишь тогда, когда на элементах хеш-таблицы задан линейный порядок. То есть при использовании данный типа [math]\mathbf[/math] или [math]\mathbf[/math] имеет смысл переходить к дереву поиска, а при использовании каких-нибудь ссылок на объекты не имеет, так как они не реализуют нужный интерфейс. Такой подход позволяет улучшить производительность с [math]O(n)[/math] до [math]O(\log(n))[/math] . Данный способ используется в таких коллекциях как HashMap, LinkedHashMap и ConcurrentHashMap.
neerc.ifmo.ru
Разрешение коллизий
Разрешение коллизий (англ. collision resolution) в хеш-таблице, задача, решаемая несколькими способами: метод цепочек, открытая адресация и т.д. Очень важно сводить количество коллизий к минимуму, так как это увеличивает время работы с хеш-таблицами.
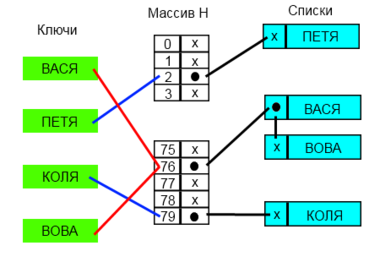
Каждая ячейка [math]i[/math] массива [math]H[/math] содержит указатель на начало списка всех элементов, хеш-код которых равен [math]i[/math] , либо указывает на их отсутствие. Коллизии приводят к тому, что появляются списки размером больше одного элемента.
В зависимости от того нужна ли нам уникальность значений операции вставки у нас будет работать за разное время. Если не важна, то мы используем список, время вставки в который будет в худшем случае равна [math]O(1)[/math] . Иначе мы проверяем есть ли в списке данный элемент, а потом в случае его отсутствия мы его добавляем. В таком случае вставка элемента в худшем случае будет выполнена за [math]O(n)[/math]
Время работы поиска в наихудшем случае пропорционально длине списка, а если все [math]n[/math] ключей захешировались в одну и ту же ячейку (создав список длиной [math]n[/math] ) время поиска будет равно [math]\Theta(n)[/math] плюс время вычисления хеш-функции, что ничуть не лучше, чем использование связного списка для хранения всех [math]n[/math] элементов.
Стратегии поиска [ править ]
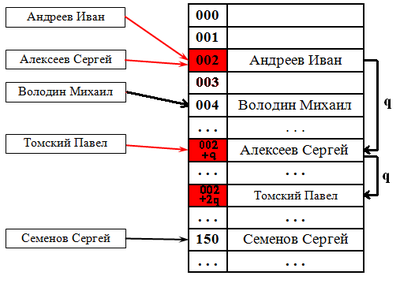
Шаг [math]q[/math] не фиксирован, а изменяется квадратично: [math]q = 1,4,9,16. [/math] . Соответственно при попытке добавить элемент в занятую ячейку [math]i[/math] начинаем последовательно просматривать ячейки [math] i+1, i+4, i+9[/math] и так далее, пока не найдём свободную ячейку.
Проверка наличия элемента в таблице [ править ]
Проверка осуществляется аналогично добавлению: мы проверяем ячейку [math]i[/math] и другие, в соответствии с выбранной стратегией, пока не найдём искомый элемент или свободную ячейку.
При поиске элемента может получится так, что мы дойдём до конца таблицы. Обычно поиск продолжается, начиная с другого конца, пока мы не придём в ту ячейку, откуда начинался поиск.
Проблемы данных стратегий [ править ]
Удаление элемента без пометок [ править ]
Рассуждение будет описывать случай с линейным поиском хеша. Будем при удалении элемента сдвигать всё последующие на [math]q[/math] позиций назад. При этом:
Учитывая это будем действовать следующим образом: при поиске следующего элемента цепочки будем пропускать все ячейки с другим значением хеша, первый найденный элемент копировать в текущую ячейку, и затем рекурсивно его удалять. Если такой следующей ячейки нет, то текущий элемент можно просто удалить, сторонние цепочки при этом не разрушатся (чего нельзя сказать про случай квадратичного поиска).
Вариант с зацикливанием мы не рассматриваем, поскольку если [math]q[/math] взаимнопросто с размером хеш-таблицы, то для зацикливания в ней вообще не должно быть свободных позиций
Докажем по индукции. Если на данной итерации мы просто удаляем элемент (база), то после него ничего нет, всё верно. Если же нет, то вызванный в конце [math]\mathrm[/math] (см. псевдокод) заметёт созданную дыру (скопированный элемент), и сам, по предположению, новых не создаст.
Принцип двойного хеширования [ править ]
При двойном хешировании используются две независимые хеш-функции [math] h_1(k) [/math] и [math] h_2(k) [/math] . Пусть [math] k [/math] — это наш ключ, [math] m [/math] — размер нашей таблицы, [math]n \bmod m [/math] — остаток от деления [math] n [/math] на [math] m [/math] , тогда сначала исследуется ячейка с адресом [math] h_1(k) [/math] , если она уже занята, то рассматривается [math] (h_1(k) + h_2(k)) \bmod m [/math] , затем [math] (h_1(k) + 2 \cdot h_2(k)) \bmod m [/math] и так далее. В общем случае идёт проверка последовательности ячеек [math] (h_1(k) + i \cdot h_2(k)) \bmod m [/math] где [math] i = (0, 1, \; . \;, m — 1) [/math]
Выбор хеш-функций [ править ]
[math] h_1 [/math] может быть обычной хеш-функцией. Однако чтобы последовательность исследования могла охватить всю таблицу, [math] h_2 [/math] должна возвращать значения:
Например, если размер таблицы равен [math] m [/math] , то в качестве [math] h_2 [/math] можно использовать функцию вида [math] h_2(k) = k \bmod (m-1) + 1 [/math]
Показана хеш-таблица размером 13 ячеек, в которой используются вспомогательные функции:
[math] h_1(k) = k \bmod 13 [/math]
[math] h_2(k) = 1 + k \bmod 11 [/math]
Алгоритмы хеширования данных
Цель лекции: изучить построение функции хеширования и алгоритмов хеширования данных и научиться разрабатывать алгоритмы открытого и закрытого хеширования при решении задач на языке C++.
Процесс поиска данных в больших объемах информации сопряжен с временными затратами, которые обусловлены необходимостью просмотра и сравнения с ключом поиска значительного числа элементов. Сокращение поиска возможно осуществить путем локализации области просмотра. Например, отсортировать данные по ключу поиска, разбить на непересекающиеся блоки по некоторому групповому признаку или поставить в соответствие реальным данным некий код, который упростит процедуру поиска.
В настоящее время используется широко распространенный метод обеспечения быстрого доступа к информации, хранящейся во внешней памяти – хеширование .
Хеширование (или хэширование, англ. hashing ) – это преобразование входного массива данных определенного типа и произвольной длины в выходную битовую строку фиксированной длины. Такие преобразования также называются хеш-функциями или функциями свертки , а их результаты называют хешем, хеш-кодом, хеш-таблицей или дайджестом сообщения (англ. message digest ).
Хеш-таблица – это структура данных , реализующая интерфейс ассоциативного массива, то есть она позволяет хранить пары вида » ключ — значение » и выполнять три операции : операцию добавления новой пары, операцию поиска и операцию удаления пары по ключу. Хеш-таблица является массивом, формируемым в определенном порядке хеш-функцией .
Принято считать, что хорошей, с точки зрения практического применения, является такая хеш-функция , которая удовлетворяет следующим условиям:
При этом первое свойство хорошей хеш-функции зависит от характеристик компьютера, а второе – от значений данных.
Если бы все данные были случайными, то хеш-функции были бы очень простые (например, несколько битов ключа). Однако на практике случайные данные встречаются достаточно редко, и приходится создавать функцию, которая зависела бы от всего ключа. Если хеш-функция распределяет совокупность возможных ключей равномерно по множеству индексов, то хеширование эффективно разбивает множество ключей. Наихудший случай – когда все ключи хешируются в один индекс .
При возникновении коллизий необходимо найти новое место для хранения ключей, претендующих на одну и ту же ячейку хеш-таблицы. Причем, если коллизии допускаются, то их количество необходимо минимизировать. В некоторых специальных случаях удается избежать коллизий вообще. Например, если все ключи элементов известны заранее (или очень редко меняются), то для них можно найти некоторую инъективную хеш-функцию, которая распределит их по ячейкам хеш-таблицы без коллизий . Хеш-таблицы, использующие подобные хеш-функции , не нуждаются в механизме разрешения коллизий , и называются хеш-таблицами с прямой адресацией.
Хеш-таблицы должны соответствовать следующим свойствам.
Хеширование полезно, когда широкий диапазон возможных значений должен быть сохранен в малом объеме памяти, и нужен способ быстрого, практически произвольного доступа. Хэш-таблицы часто применяются в базах данных, и, особенно, в языковых процессорах типа компиляторов и ассемблеров , где они повышают скорость обработки таблицы идентификаторов. В качестве использования хеширования в повседневной жизни можно привести примеры распределение книг в библиотеке по тематическим каталогам, упорядочивание в словарях по первым буквам слов, шифрование специальностей в вузах и т.д.
Методы разрешения коллизий
Коллизии осложняют использование хеш-таблиц, так как нарушают однозначность соответствия между хеш-кодами и данными. Тем не менее, существуют способы преодоления возникающих сложностей:
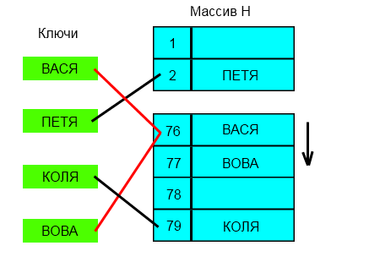
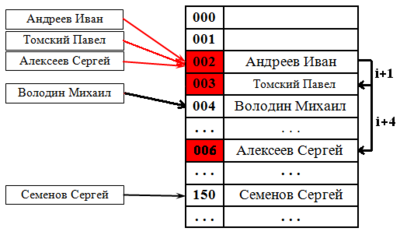
Метод цепочек. Технология сцепления элементов состоит в том, что элементы множества , которым соответствует одно и то же хеш- значение , связываются в цепочку- список . В позиции номер i хранится указатель на голову списка тех элементов, у которых хеш- значение ключа равно i ; если таких элементов в множестве нет, в позиции i записан NULL . На рис. 38.1 демонстрируется реализация метода цепочек при разрешении коллизий . На ключ 002 претендуют два значения, которые организуются в линейный список .

Каждая ячейка массива является указателем на связный список (цепочку) пар ключ — значение , соответствующих одному и тому же хеш-значению ключа. Коллизии просто приводят к тому, что появляются цепочки длиной более одного элемента.
Операции поиска или удаления данных требуют просмотра всех элементов соответствующей ему цепочки, чтобы найти в ней элемент с заданным ключом. Для добавления данных нужно добавить элемент в конец или начало соответствующего списка, и, в случае если коэффициент заполнения станет слишком велик, увеличить размер массива и перестроить таблицу.
При предположении, что каждый элемент может попасть в любую позицию таблицы с равной вероятностью и независимо от того, куда попал любой другой элемент, среднее время работы операции поиска элемента составляет O(1+k) , где k – коэффициент заполнения таблицы.
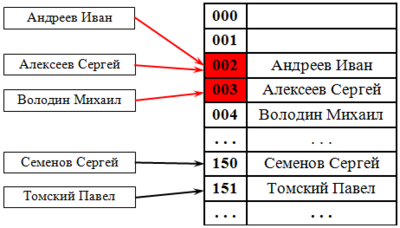
Метод открытой адресации. В отличие от хеширования с цепочками, при открытой адресации никаких списков нет, а все записи хранятся в самой хеш-таблице. Каждая ячейка таблицы содержит либо элемент динамического множества , либо NULL .
В этом случае, если ячейка с вычисленным индексом занята, то можно просто просматривать следующие записи таблицы по порядку до тех пор, пока не будет найден ключ K или пустая позиция в таблице. Для вычисления шага можно также применить формулу, которая и определит способ изменения шага. На рис. 38.2 разрешение коллизий осуществляется методом открытой адресации. Два значения претендуют на ключ 002, для одного из них находится первое свободное (еще незанятое) место в таблице.

При любом методе разрешения коллизий необходимо ограничить длину поиска элемента. Если для поиска элемента необходимо более 3 – 4 сравнений, то эффективность использования такой хеш-таблицы пропадает и ее следует реструктуризировать (т.е. найти другую хеш-функцию), чтобы минимизировать количество сравнений для поиска элемента
Для успешной работы алгоритмов поиска, последовательность проб должна быть такой, чтобы все ячейки хеш-таблицы оказались просмотренными ровно по одному разу.
Удаление элементов в такой схеме несколько затруднено. Обычно поступают так: заводят логический флаг для каждой ячейки, помечающий, удален ли элемент в ней или нет. Тогда удаление элемента состоит в установке этого флага для соответствующей ячейки хеш-таблицы, но при этом необходимо модифицировать процедуру поиска существующего элемента так, чтобы она считала удаленные ячейки занятыми, а процедуру добавления – чтобы она их считала свободными и сбрасывала значение флага при добавлении.
www.intuit.ru